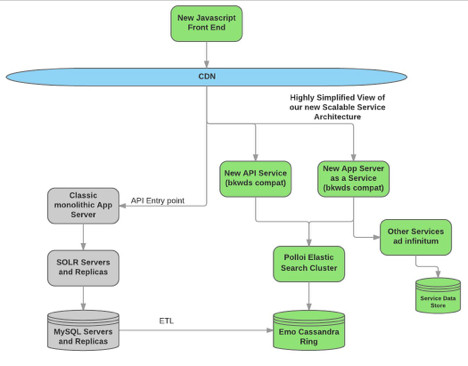
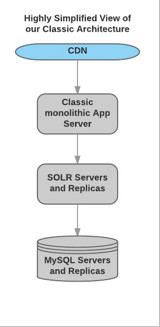
How Bazaarvoice moved 300 million shoppers to a new generation platform Part 3
{This is the final post in a 3 part series intended to tell the story of how we have been able to achieve an epic rearchitecture of our core platform. Special thanks to all of those who have helped in review and editing the original white paper.}
Rearchitecting the Team
In addition to rearchitecting the service to scale, we also had to rearchitect our team. As we set out on this journey to rebuild our solution into a scalable, cloud based service oriented architecture, we had to reconsider the very way our teams are put together. We reimagined our team structure to include all the ingredients the team needs to go fast. This meant a big investment in devops – engineers that focus on new architectures, deployment, monitoring, scalability, and performance in the cloud.
A critical part of this was a cultural transformation where the service is completely owned by the team, from understanding the requirements, to code, to automated test, to deployment, to 24×7 operation. This means building out a complete monitoring and alerting infrastructure and that the on-call duty rotated through all members of the team. The result is the team becomes 100% aligned around the success of the service and there is no wall to throw anything over – the commitment and ownership stays with the team.
For this team architecture to succeed, the critical element is to ensure the team has all the skills and team players needed to succeed. This means platform services to support the team, strong product and program managers, talented QA automation engineers that can build on a common automation platform, gifted technical writers, and of course highly talented developers. These teams are built to learn fast, build fast, and deploy fast, completely independent of other teams.
Supporting the service-oriented teams, a key element is our Platform Infrastructure team we created to provide a common set of cloud services to support all our teams. Platform Infrastructure is responsible for the virtual private cloud (VPC) supporting the new services running in amazon web services. This team handles the overall concerns of security, network, service discovery, and other common services within the VPC. They also set up a set of best practices, such as ensuring all cloud instances are tagged with the name of the team that started them.
To ensure the best practices are followed, the platform infrastructure team created Beavers (a play on words describing a engineer at Bazaarvoice, a BVer). An idea borrowed from Netflix’s chaos monkeys, these are automated processes that run and examine our cloud environment in real time to ensure the best practices are followed. For example, the Conformity Beaver runs regularly and checks to make sure all instances and buckets are tagged with team names. If it finds one that is not, it infers the owner and emails team aliases of the problem. If not corrected, Conformity Beaver can terminate the instance. This is just one example of the many Beavers we have created to help maintain consistency in a world where we have turned teams lose to move as quickly as possible.
An additional key common capability created by the Platform Infrastructure team is our Badger monitoring services. Badger enables teams to easily plug in a common healthcheck monitoring capability and can automatically discover nodes as they are started in the cloud. This service enables teams to easily implement these healthcheck that is captured in a common place and escalated through a notification system in the event of a service degradation.
The Proof is in the Pudding
The Black Friday and Holiday shopping season of 2015 was one of the smoothest ever in the history of Bazaarvoice while serving record traffic. From Black Friday to Cyber Monday, we saw over 300 million visitors. At peak on Black Friday, we were seeing over 97,000 requests per second as we served up over 2.6 billion review impressions, a 20% increase over the year before. Â There have been years of hard work and innovation that preceded this success and it is a testimony to what our new architecture is capable of delivering.
Keys to success
A few ingredients we’ve found to be important to successfully pull off a large scale rearchitecture such as described here:
- Brilliant people. There is no replacement for brilliant engineers who are fearless in adopting new technologies and tackling what some will say can’t be done.
- Strong leaders – and the right leaders at the right time. Often the leaders that sell the vision and get an undertaking like this going will need to be supplemented with those that can finish strong.
- Perseverance and Determination – building a new platform using new technologies is going to be a much bigger challenge than you can estimate, requiring new skills, new approaches, and lots of mistakes. You must be completely determined and focused on the end game.
- Tie back to business benefit – keep business informed of the benefits and ensuring that those benefits can be delivered continuously rather than a big bang. It will be a large investment and it is important that the business see some level of return as quickly as possible.
- Make space for innovation – create room for engineers to learn and grow. We support this through organizing hackathons and time for growth projects that benefit the individual, team, and company.
Reachitecture is a Journey
One piece of advice: don’t be too critical of yourself along the way; celebrate each step of the reachitecture journey. As software engineers, we are driven to see things “complete”, wrapped up nice and neat, finished with a pretty bow. When replacing an existing system of significant complexity, this ideal is a trap because in reality you will never be complete. It has taken us over 3 years of hard work to reach this point, and there are more things we are in the process of moving to newer architectures. Once we complete the things in front of us now, there will be more steps to take since we live in an ever evolving landscape. It is important to remember that we can never truly be complete as there will be new technologies, new architectures that deliver more capabilities to your customers, faster, and at a lower cost. Its a journey.
Perhaps that is the reason many companies can never seem to get started. They understandably want to know “When will it be done?” “What is it going to cost?”, and the unpopular answers are of course, never and more than you could imagine. The solution to this puzzle is to identify and articulate the business value to be delivered as a step in the larger design of a software platform transformation. Trouble is of course, you may only realistically be able to design the first few steps of your platform rearchitecture, leaving a lot of technical uncertainty ahead. Get comfortable with it and embrace it as a journey. Engineer solid solutions in a service oriented way with clear interfaces and your customers will be happy never knowing they were switched to the next generation of your service.