Cloud Computing11 Dec 2017 05:54 am
Tips for AWS Solutions Architect Associate Exam and Tips for AWS Developer Associate Exam
Time to dedicate to this blog has been little and far between, but I resolve to make it more frequent this coming year. Just completed my second AWS certification and thought I’d write a few notes here to hopefully help others.  The blueprint I have found successful:
- First, I would heavily recommend acloud.guru training courses as prep for the exam. It is a great foundation to start from. The courses are exceptionally well done, very affordable, and give great exam tips. Â These were recommended to me by at the 2016 reinvent and it was a great suggestion. Just do it.
- There’s no substitute for experience.  I’m convinced if not for my years of experience with TCP/IP, software development, network configuration, etc, I would not have passed the exams.  While I don’t have deep experience developing on AWS, my background with AWS, years of experience, plus the acloud.guru prep was a winning combination.
- Read the FAQs. Yes, they are more than 120 chars long. Â They may take you quite a while to get through, but it is very helpful for the exam.
- Google for AWS Solution Architect Associate Exam Tips or AWS Developer Associate Exam Tips.  That’s probably how you found this post so you’re ahead of the game.  Read the tips people give.
- If you are working full time, and have a family, allow 3-4 months per test.  Yeah, it takes that long, but hey you’re probably smarter than me.
- The test is at least a year behind the AWS services. AWS is undergoing such rapid innovation that the certification exams have a hard time keeping up. Â Here, acloud.guru and google searches really pay off as they will tend to keep you at the current state of the certification exams, vs the current state of AWS.
Experience with the AWS Solutions Architect Associate exam:
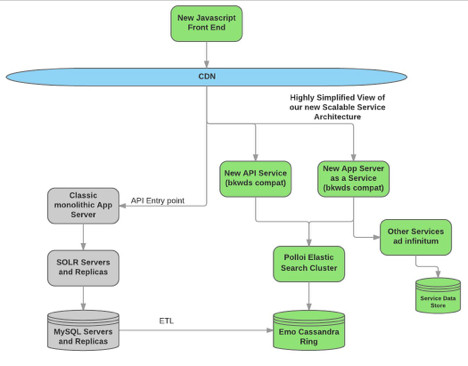
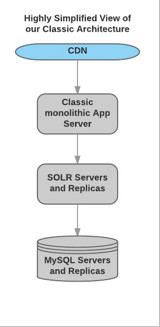
Took this exam in Jan 2017. The largest topics on this exam were VPCs, S3, and EC2, with a bit of Route 53 thrown in for good measure. Â Take the acloud.guru course. Â You need to read the S3 FAQ (yes the minimum file size is 0 bytes), and understand VPCs, including NAT instances. Â Know all your HTTP return codes. Â Know SQS vs SNS. Know Alias records, A records, and the rest of Route 53. I recall mutiple security questions – read the well architected framework and AWS security best practices in addition to the Shared Responsibility model document. Â All of this is good practical knowledge in addition to being essential to scoring well on the exam.
I took this exam first and felt it was pretty difficult. Â I scored in the 80s and was happy to achieve the score. Â Some of the questions are straight single answer multiple choice, but many are pick 2 and even some pick 3 answer variations. Â These are not fun.
Experience with the AWS Certified Developer Associate exam
Took this exam at reinvent 2017 (November 2017). Having completed the Solutions Architect exam made this exam easier.  As you’d guess, it is more developer centric, but also has a fair amount of overlap with the Solutions Architect. The overlap areas are VPC, S3, Route53 and a bit of EC2 (I think we all know what happens to instance based storage with the instance terminates, heh?). SQS and SNS were also represented by about 5 or so questions on the Developer Associate exam.  I think there was 1 question on SWF.
Where the exams differ is the Developer exam is heavy on DynamoDB – at least 3 questions on calculating different kinds of read and write throughput. Also, there are specific questions on API cals. Read the S3 API, DynamoDB API, and understand how Federated authentication works (AssumeRoleWithWebIdentity, AssumeRoleWithSAML).
There were one or two questions featuring API syntax, but if you are firmly rooted in the principles, you can pick the right answer without memorizing the syntax. Â CloudFormation, ElasticBeanstalk and the SDKs were covered at a high-level with a few questions (certainly know what languages are supported for each).
While I won’t give away the specific questions on the exam, there is one that I found so humorous that must be shared. The question had to do with legitimate endpoints for SNS and one of the choices was Named Pipes.  Now that was a blast from the past!  I almost laughed out loud in the exam.  Whomever wrote that question, I salute you.
Know your limits for both Certification Exams
Found it handy for studying to create a table of minimums and maximums for various services in AWS. Â This is accurate as of Nov 2017, but beware that these can and do change. Â But then again, you have a year before they update the exam. Â Hope it is helpful. Â Good luck!
|
Service
|
Min
|
Max
|
Notes
|
|
S3 object size
|
0
|
5TB
|
Single PUT limit is 5G, but should use multi-part upload for anything larger than 100Mb
|
|
S3 buckets
|
100
|
Call AWS to raise limit
|
|
|
S3 Availability
|
99.9 for IA
|
99.99 for Standard
|
|
|
DynamoDB
|
1 byte
|
400K
|
|
|
DynamoDB block size
|
1K writes
|
4K reads
|
Eventual consistent Reads are 2/sec, Strongly consistent Reads are 1/sec, All Writes are 1/sec
|
|
DynamoDB BatchWriteItem
|
25 items, up to 16MB
|
||
|
DynamoDB BatchGetItem
|
100 items, up to 16MB
|
||
|
DynamoDB Query
|
1Mb max returned
|
||
|
DynamoDB Global Sec Index
|
5 max
|
partition key can be on any attribute
|
|
|
SQS Default Visibility Timeout
|
30 sec
|
12 hours
|
Extend the timeout by calling ChangeMessageVisibility
|
|
SQS Message Delay
|
15 mins
|
||
|
SQS Message Size
|
256K
|
Billed in 64K chunks
|
|
|
SQS Requests
|
1 message
|
10 messages
|
Up to 256K
|
|
SQS retention
|
14 days
|
||
|
SQS Long Polling
|
20 sec
|
Maximum long polling time out is 20 seconds for SQS
|
|
|
SNS Topics
|
256 chars
|
||
|
SWF Retention
|
1 year
|

 Recently, a tragedy hit one of the members on my team where he lost his home. Our team has rallied around him and his family and have done what we can to help – that’s just the kind of people I’m fortunate enough to work with. In talking to him, one of his regrets is that he didn’t have his photos backed up offsite. He said he looked into it, but then just didn’t get around to it. That was inspiration to get me moving…
Recently, a tragedy hit one of the members on my team where he lost his home. Our team has rallied around him and his family and have done what we can to help – that’s just the kind of people I’m fortunate enough to work with. In talking to him, one of his regrets is that he didn’t have his photos backed up offsite. He said he looked into it, but then just didn’t get around to it. That was inspiration to get me moving…

 9:20 Marc Benioff has just taken the stage – quite a showman he is. Nice video overview of day 1. Benioff now talking about Microsoft as the evil empire – says they are trying to stop chatter, the sales cloud, and his new socks. Talking now about the Microsoft lawsuit – and Micosoft “protest” outside yesterday. (MS had seqway drivers out front with “Don get Forced” slogans.)
9:20 Marc Benioff has just taken the stage – quite a showman he is. Nice video overview of day 1. Benioff now talking about Microsoft as the evil empire – says they are trying to stop chatter, the sales cloud, and his new socks. Talking now about the Microsoft lawsuit – and Micosoft “protest” outside yesterday. (MS had seqway drivers out front with “Don get Forced” slogans.)


 It’s been a busy week as usual this time of year, but right in the middle of the week appeared my very own shiny Droid phone. I’m still just a little in awe that Google has offered a new Android based phone to everyone at the conference. Wow, what an impressive display of financial clout. I feel it is a smart move – to get the people that obviously care most about what Google is doing to get interested in building Android apps.
It’s been a busy week as usual this time of year, but right in the middle of the week appeared my very own shiny Droid phone. I’m still just a little in awe that Google has offered a new Android based phone to everyone at the conference. Wow, what an impressive display of financial clout. I feel it is a smart move – to get the people that obviously care most about what Google is doing to get interested in building Android apps.